Uber数据基础架构 现状与未来数据处理服务展望
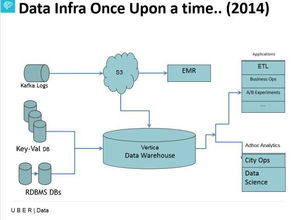
Uber作为全球领先的出行和配送平台,其数据基础架构承载着海量实时和历史数据的处理需求。当前,Uber的数据基础架构以可扩展性、可靠性和实时性为核心,支撑着从行程匹配到动态定价、安全监控等关键业务。数据处理服务已形成完整的生态系统,包括数据采集、存储、计算和分析等环节。
在现状方面,Uber依赖Apache Kafka进行实时数据流处理,使用Hadoop和Spark进行批处理分析,并采用Presto和Apache Flink支持交互式查询与复杂事件处理。其自研的 Michelangelo 机器学习平台整合了数据处理流程,助力模型训练与部署。数据存储层则结合了OLAP和OLTP系统,如MySQL、Cassandra和列式存储,确保数据的高效访问。
面向未来,Uber数据基础架构将朝着更智能、自动化和云原生方向发展。数据处理服务将进一步集成AI和ML能力,实现预测性维护和动态资源优化,以降低运营成本。随着边缘计算的兴起,Uber将加强实时数据处理在本地设备端的部署,提升低延迟响应能力,尤其在自动驾驶和物联网场景中。数据治理和隐私保护将成为重点,通过加密技术和合规框架确保用户数据安全。
另一个关键趋势是多云和混合云策略的深化,Uber计划利用云服务(如AWS、GCP)的弹性,结合自建数据中心,实现资源无缝扩展。同时,流批一体架构将更普及,减少数据冗余并提升处理效率。未来,Uber还可能探索量子计算在优化算法中的应用,以解决超大规模数据挑战。
Uber的数据基础架构正从传统的大数据处理向智能化、实时化和安全化演进,未来数据处理服务将更加聚焦于自动化决策、用户体验优化和可持续发展,为全球业务提供坚实支撑。
如若转载,请注明出处:http://www.keyou888.com/product/8.html
更新时间:2026-02-25 21:07:52









